问题:机器翻译
模型评估标准
BLEU(Bilingual Evaluation Understudy)是一种用于评估机器生成文本质量的指标,特别是在机器翻译的背景下。用于评估机器生成的翻译与一个或多个参考翻译之间的相似性。
BLEU分数的范围是0到1,其中1表示机器生成文本与参考翻译完全匹配。较高的BLEU分数通常表示更好的性能,但需要注意的是,BLEU有其局限性,不总是与人类对翻译质量的判断完全一致。它不能捕捉流畅度、语法或语义含义等方面,有时可能偏向过于字面的翻译。
n-gram表示文本中连续的n个项。其中,n是使用的n-gram级别。通常情况下,BLEU计算中使用1-gram到4-gram。 \[BLEU=exp(min(0,1-\frac{len_{label}}{len_{pred}}))\prod_{n=1}^k{p_n^{1/2^n}}\]
- \(p_n\)是预测中所有n-gram的精度。 \[p_n=\frac{预测序列中n-gram在标签序列中匹配的次数}{预测序列中n-gram的总数}\] 例如,标签序列为A B C D E F,预测序列为A B B C D中
- \(p_1=4/5\),即预测序列1-gram为A B B C D,A有匹配,第一个B有匹配,第二个B没有匹配,C有匹配,D有匹配。
- \(p_2=3/4\),即预测序列2-gram为AB BB BC CD,AB有匹配,BB没有匹配,BC有匹配,CD有匹配
- \(p_3=1/3\)
- \(p_4=0\)
展开来看BLEU: - \(exp(min(0,1-\frac{len_{label}}{len_{pred}}))\)当预测序列的长度小于标签序列的长度时:这个值为1,这里是为了惩罚过短的预测。
- \(\prod_{n=1}^k{p_n^{1/2^n}}\)一般k取4。当n=4时次数靠近于0,是为了长匹配有高权重。
这样一个惩罚过短的预测,一个给长匹配有高权重。
BLEU函数代码
1 | import math |
模型:seq2seq
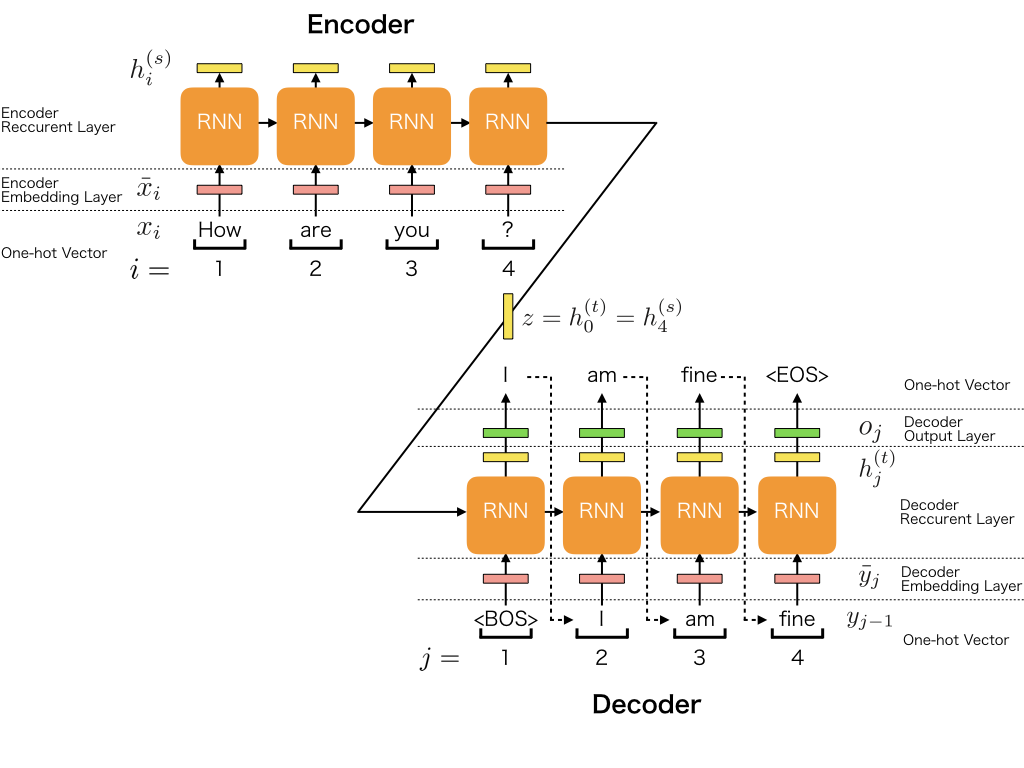 # 损失函数
使用mask的CrossEntropyLoss,mask相当于在原始张量上盖上一层掩膜,从而屏蔽或选择一些特定元素。
# 损失函数
使用mask的CrossEntropyLoss,mask相当于在原始张量上盖上一层掩膜,从而屏蔽或选择一些特定元素。
代码实现
import 1
2
3
4
5import torch
from torch import nn
from d2l import torch as d2l
import pandas as pd
from torch.utils.data import DataLoader1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder) -> None:
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.enc_state = None
self.dec_state = None
def forward(self, X, X_valid_len, Y, Y_valid_len):
enc_output, enc_state = self.encoder(X, X_valid_len)
dec_output, dec_state = self.decoder(Y, enc_state, Y_valid_len)
self.enc_state = enc_state
self.dec_state = dec_state
return dec_output
class Seq2seqEncoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers) -> None:
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers)
def forward(self, x: torch.Tensor, *args):
x = self.embedding(x)
x = x.permute(1,0,2)
# seq2seq的encoder的state是不需要保持之前的结构
output, state = self.rnn(x)
return output, state
class Seq2seqDecoder(nn.Module):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers) -> None:
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size+num_hiddens, num_hiddens, num_layers)
self.linear = nn.Linear(num_hiddens, vocab_size)
def forward(self, x:torch.Tensor, state:torch.Tensor, *args):
# input x shape (batch_size, num_steps, embed_size)
# input state shape (num_layers, batch_size, num_hiddens), only need last layer.so (batch_size, num_hiddens)
x = self.embedding(x).permute(1,0,2) # x shape (num_steps, batch_size, vocab_size)
context = state[-1].repeat(x.shape[0],1,1) # context shape (num_steps, batch_size, num_hiddens)
x = torch.cat((x,context), dim=2)
output, state = self.rnn(x, state)
output = self.linear(output).permute(1,0,2)
return output, state
def sequence_mask(X, valid_len, value=0):
# X shape: batch_size * sequence_size
batch_size, maxlen = X.size(0), X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32, device=X.device).repeat(batch_size, 1)
valid_len = valid_len.reshape(-1, 1)
mask = mask < valid_len
X[~mask] = value
return X
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39def tokens(path):
eng = []
chin = []
with open(path, 'r', encoding='utf-8') as f:
txt = f.read()
for i,line in enumerate(txt.split('\n')):
line = line.split('\t')
line[0] = ''.join([' '+word if word in set(',.!?') else word for word in line[0].lower()])
line[0] = line[0].split(' ')
line[1] = list(line[1].replace(' ', ''))
eng.append(line[0])
chin.append(line[1])
return chin, eng
def vocab_fn(tokens):
seqs = []
for seq in tokens:
seqs += seq
return d2l.Vocab(seqs, min_freq=2, reserved_tokens=['<pad>', '<bos>', '<eos>'])
class Eng2chinSet(object):
def __init__(self, chin_vocab, eng_vocab, chin2engs, seq_size) -> None:
self.chin_vocab, self.eng_vocab, self.seq_size = chin_vocab, eng_vocab, seq_size
self.data = pd.DataFrame(chin2engs).T
def corp_seq(self, seq, seq_size, vocab):
n = len(seq)
if n>= seq_size:
return seq[:seq_size-1]+[vocab['<eos>']], seq_size
else:
pads = [vocab['<pad>'] for _ in range(seq_size-n-1)]
return seq + [vocab['<eos>']] +pads, n+1
def __getitem__(self, idx):
chin_seq, eng_seq = self.data.iloc[idx, :]
chin_seq, chin_valid_len= self.corp_seq(self.chin_vocab[chin_seq], self.seq_size[0], self.chin_vocab)
eng_seq, eng_valid_len= self.corp_seq(self.eng_vocab[eng_seq], self.seq_size[1], self.eng_vocab)
chin_seq, chin_valid_len, eng_seq, eng_valid_len = [torch.tensor(x) for x in [chin_seq, chin_valid_len, eng_seq, eng_valid_len]]
return chin_seq, chin_valid_len, eng_seq, eng_valid_len
def __len__(self):
return self.data.shape[0]
train
1 | path = '/kaggle/input/english2chinese-simple-dataset/eng-chi.txt' |
predict
1 | def predict_seq2seq(net, chin_sentence, chin_vocab, eng_vocab, num_steps,device): |
可以看到其实翻译效果一般,原因可能是数据集太小和模型太小。