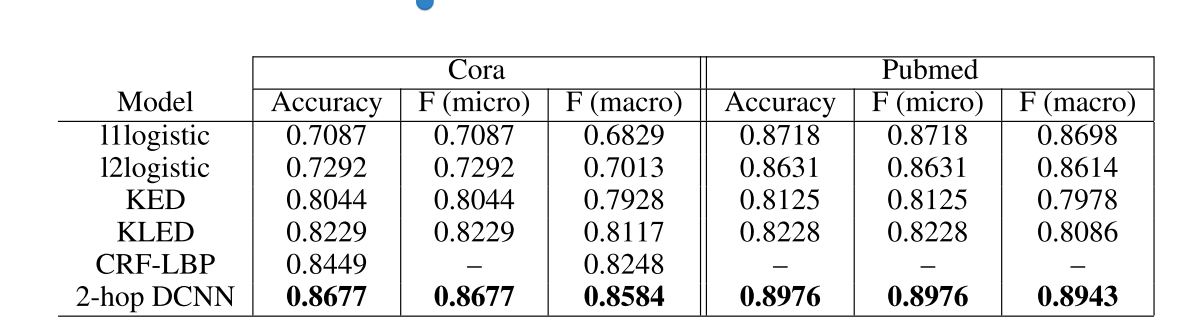
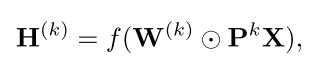1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| from torch_geometric.datasets import Planetoid
import matplotlib.pyplot as plt
def edge_index_to_adj(num_nodes, edge_index):
adj = torch.zeros((num_nodes, num_nodes), dtype=torch.float32, device=edge_index.device)
for i,j in edge_index.T:
adj[i, j]=1
adj[j, i]=1
return adj
def accuracy(y_hat, y):
y_hat = y_hat.argmax(dim=1)
score = y_hat[y_hat==y].shape[0]/y.shape[0]
return score
def test(net, cora_data, mask):
net.eval()
adj = edge_index_to_adj(cora_data.num_nodes, cora_data.edge_index)
y_hat = net(cora_data.x, adj)
return accuracy(y_hat[mask], cora_data.y[mask])
def train(net: DCNN, cora_data, device):
epochs = 200
lr, weight_decay = 0.01, 5e-4
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=weight_decay)
adj = edge_index_to_adj(cora_data.num_nodes, cora_data.edge_index)
print(adj.device)
net, cora_data = [i.to(device) for i in [net, cora_data]]
loss_list = []
val_list = []
for e in range(epochs):
net.train()
y_hat = net(cora_data.x, adj)
loss = loss_fn(y_hat[cora_data.train_mask], cora_data.y[cora_data.train_mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
val_acc = test(net, cora_data, cora_data.val_mask)
loss_list.append(loss.item())
val_list.append(val_acc)
if e%50==0 or e==epochs-1: print(e, ' ', loss.item(), ' ', val_acc)
plt.plot(loss_list)
plt.plot(val_list)
return net
device = torch.device('cuda')
dataset = Planetoid(root='./data/Cora', name='Cora')
cora_data = dataset[0]
net = DCNN(2, cora_data.num_features, dataset.num_classes)
train(net, cora_data, device)
cuda:0
0 1.9457284212112427 0.328
50 0.13217289745807648 0.722
100 0.07239208370447159 0.718
150 0.05417220667004585 0.708
199 0.04562362655997276 0.7
测试集精确度为:
test(net, cora_data, cora_data.test_mask)
0.756
|