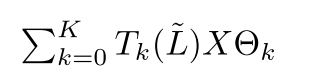1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| def test_accuracy(net, X, Y, A):
net.eval()
outs = net(X, A).argmax(dim=1)
train_outs, test_outs = outs[:140], outs[500:1500]
train_labels, test_labels = Y[:140], Y[500:1500]
train_score = train_outs[train_outs==train_labels].shape[0]/train_outs.shape[0]
test_score = test_outs[test_outs==test_labels].shape[0]/test_outs.shape[0]
return train_score, test_score
if __name__=='__main__':
from utils import load_cora
adj_path = 'Graph/data/Cora/cora.cites'
node_path = 'Graph/data/Cora/cora.content'
A, X, Y, idx_map, classes_map = load_cora(adj_path, node_path)
device = torch.device('cuda')
A, X, Y = [e.to(device) for e in [A.to_dense(), X, Y]]
epochs, lr, weight_decay =200, 0.01, 5e-4
net = ChebNet(X.shape[1], 32, len(classes_map), 2, True, 0.2).to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=weight_decay)
loss_fn = torch.nn.CrossEntropyLoss()
loss_list = []
t_total = time.time()
for e in range(epochs):
y_hat = net(X, A)
optimizer.zero_grad()
loss = loss_fn(y_hat[range(140)], Y[range(140)])
loss.backward()
optimizer.step()
loss_list.append(loss.item())
if e%10==0:
print(f'epoch:{e}, loss:{loss.item()}')
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))
print(test_accuracy(net, X, Y, A))
plt.plot(loss_list)
plt.show()
|