GRU的更新公式如下: \[ \begin{align*} z_t &= \sigma(W_{zh} \cdot h_{t-1} + W_{zx} \cdot x_t + b_z) \quad \text{(更新门)} \\ r_t &= \sigma(W_{rh} \cdot h_{t-1} + W_{rx} \cdot x_t + b_r) \quad \text{(重置门)} \\ \tilde{h}_t &= \text{tanh}(W_{hh} \cdot (r_t \odot h_{t-1}) + W_{hx} \cdot x_t + b_h) \quad \text{(候选隐藏状态)} \\ h_t &= (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t \quad \text{(最终隐藏状态)} \end{align*} \]
从零实现
1 | import torch |
超参数与数据集: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17batch_size = 32
# 一个时间步的长度
num_steps = 35
# vocab 是基于字母的标号
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size = len(vocab)
num_hiddens = 256
device= torch.device('cuda')
net = GRU(vocab_size, num_hiddens, device)
state = init_state(batch_size, num_hiddens, device)
num_epochs = 500
lr = 1
clip_value = 1.0
loss = nn.CrossEntropyLoss()
updater = torch.optim.SGD(net.params, lr=lr)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29timer = d2l.Timer()
for epoch in range(num_epochs):
metric = d2l.Accumulator(2)
for x,y in train_iter:
x,y = x.to(device), y.T.to(device)
y_hat, state = net(x, state)
l = loss(y_hat.reshape(-1, vocab_size), y.reshape(-1).long()).mean()
updater.zero_grad()
l.backward()
nn.utils.clip_grad_norm_(net.params, clip_value)
updater.step()
metric.add(l * y.numel(), y.numel())
if epoch%100 == 0 and epoch!=0:
print('困惑度:', math.exp(metric[0] / metric[1]))
print(predict('time traveller ', 100, net, vocab, device))
math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
# 输出
困惑度: 1.1065177855422412
time traveller for so it will be convenient to speak of himwas expounding a recondite matter to us his grey eyes sh
困惑度: 1.067931596405871
time traveller for so it will be convenient to speak of himwas expounding a recondite matter to us his grey eyes sh
困惑度: 1.079099433703705
time traveller with a slight accession ofcheerfulness really this is what is meant by the fourth dimensionthough so
困惑度: 1.0968159457665212
time traveller with a slight accession ofcheerfulness really this is what is meant by the fourth dimensionthough so
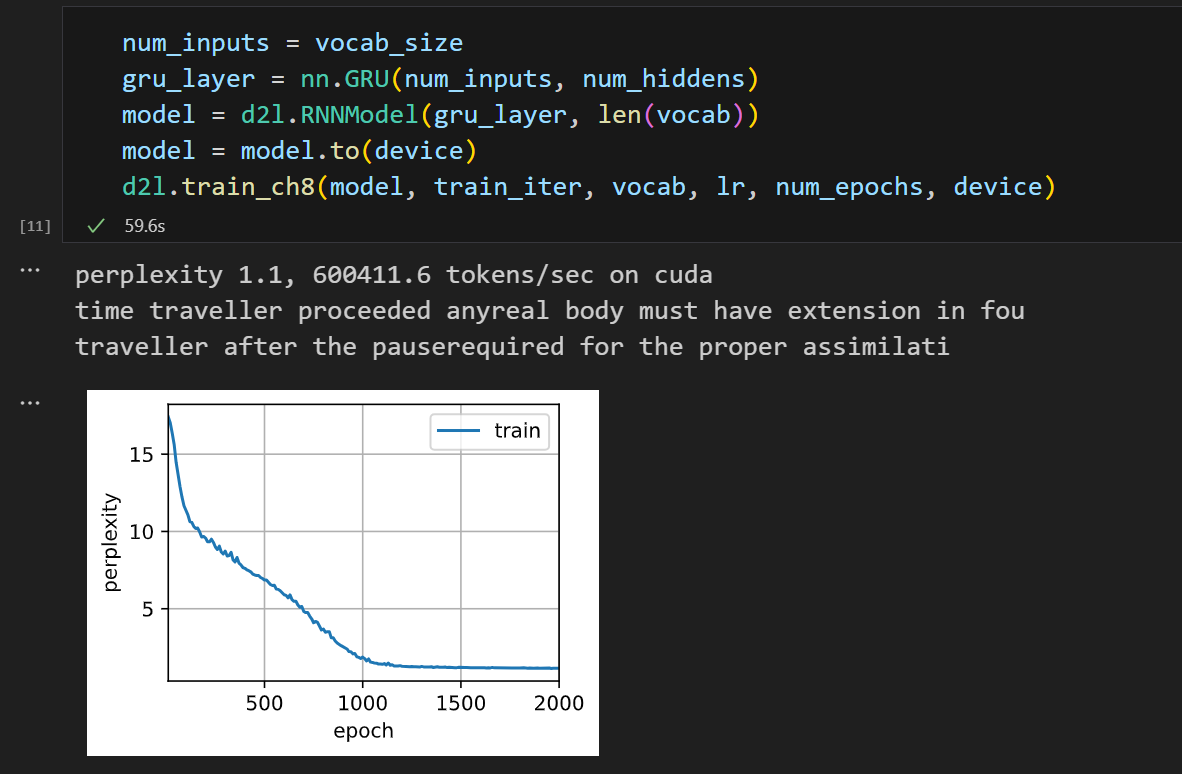
(1.0772619236579197, 46.92362845798529) 发现GRU背文章的能力不错!
发现GRU背文章的能力不错!
疑问
- batch_size=128时效果差?
发现似乎是500个epoch未能使得收敛,将epoch置为2000时