简介
@维基百科
此外K-means算法(k-平均聚类)与KNN算法(K-近邻算法)没有任何关系。
本文内容皆源自Andrew
Ng1
2
3
4
5
6
7
8
9K-平均算法(英文:k-means clustering)源于信号处理中的一种向量量化方法,现在则更多地作为一种聚类分析方
法流行于数据挖掘领域。k-平均聚类的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得
每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准。这个问题将归结为一个把数据空间
划分为Voronoi cells的问题。
这个问题在计算上是NP困难的,不过存在高效的启发式算法。一般情况下,都使用效率比较高的启发式算法,它们能够
快速收敛于一个局部最优解。这些算法通常类似于通过迭代优化方法处理高斯混合分布的最大期望算法(EM算法)。而
且,它们都使用聚类中心来为数据建模;然而k-平均聚类倾向于在可比较的空间范围内寻找聚类,期望-最大化技术却允
许聚类有不同的形状。
K-means算法思想
输入: 1.训练集,即需要进行聚类的数据,只有X没有标记Y。 2.K即聚类族的个数。
根据K随机初始化K个聚类中心。
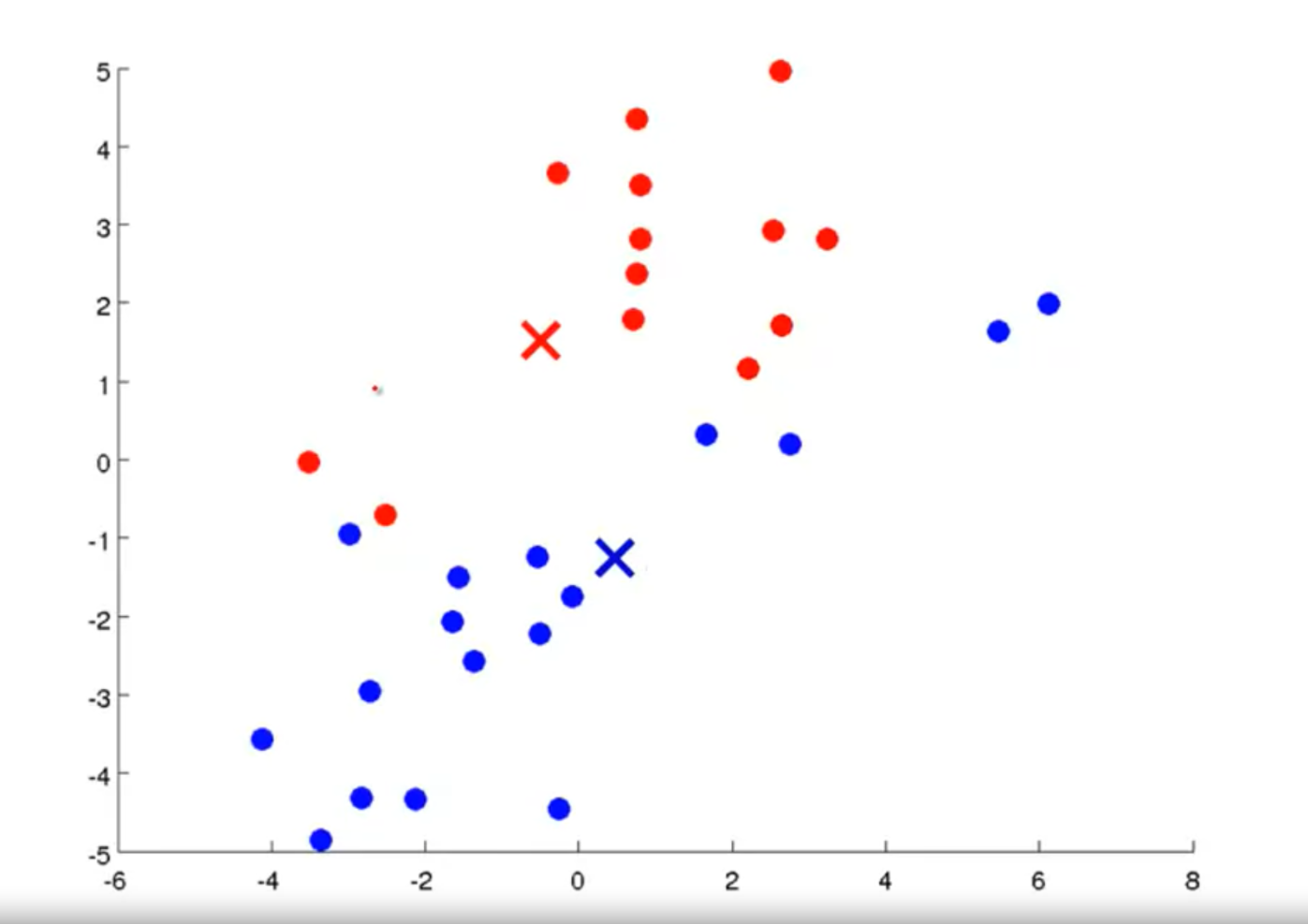
族分配。
移动聚类中心。
例如下图所示: 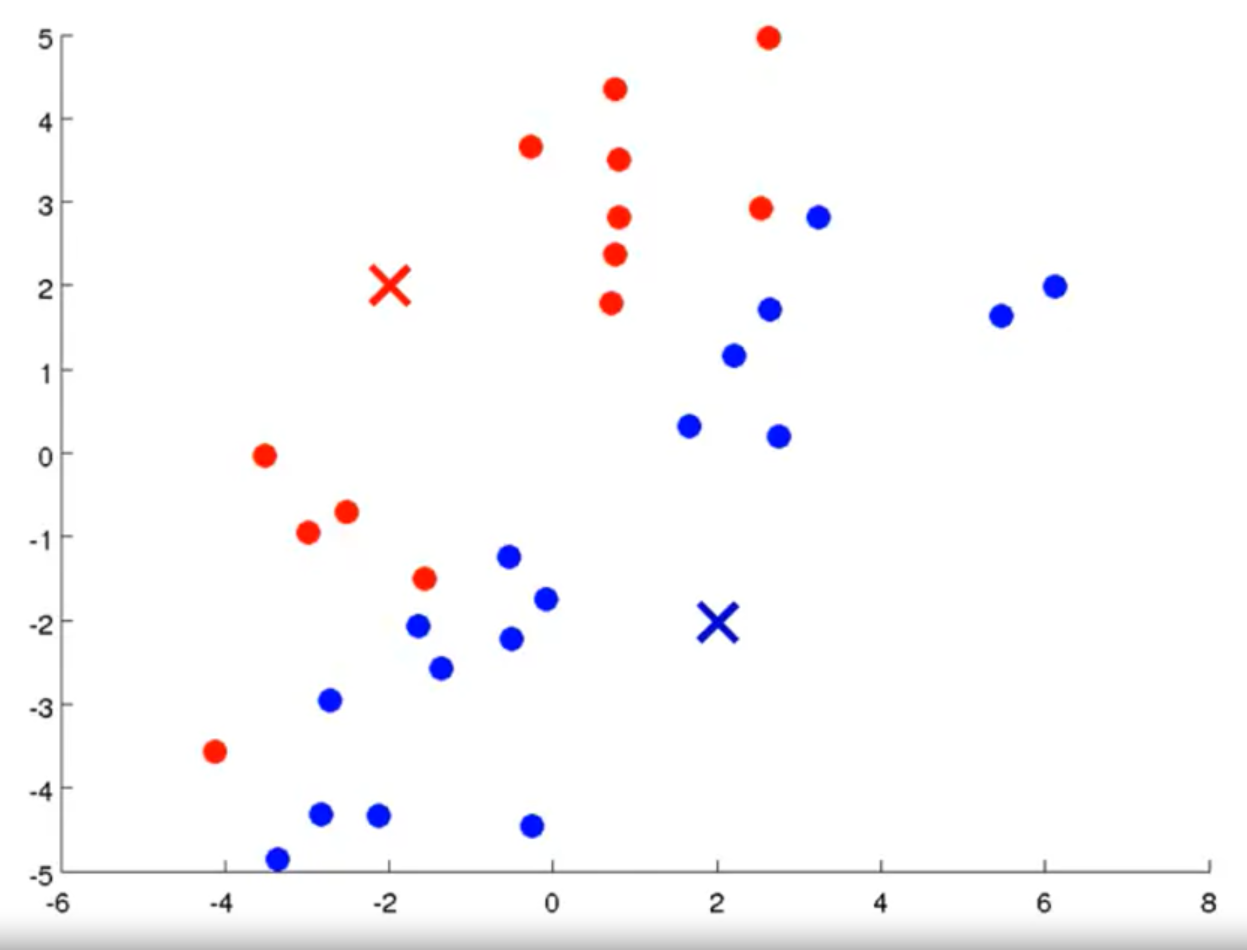
优化函数
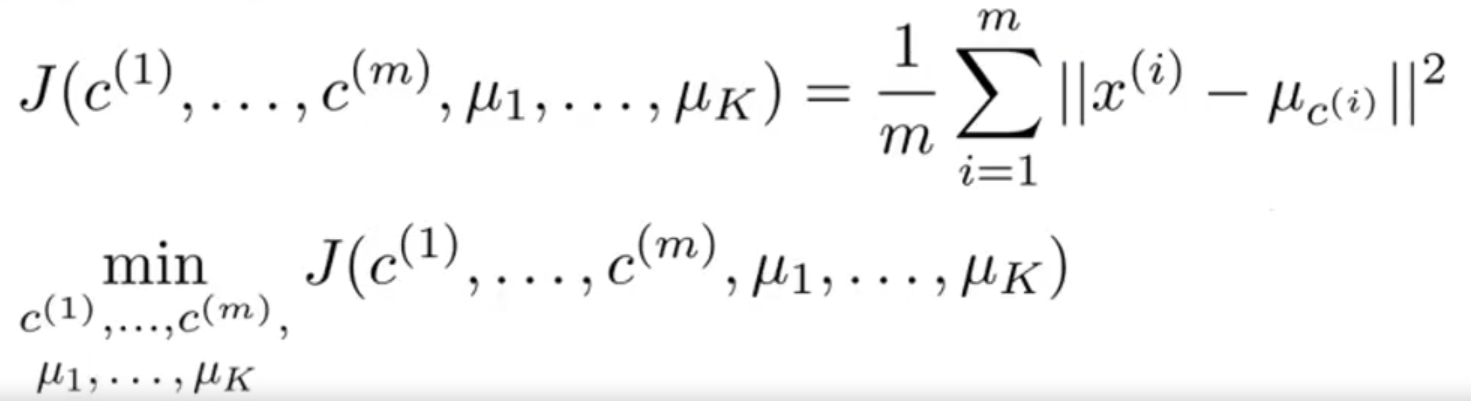
初始聚类中心的方式
随机选择K个输入点的坐标作为聚类中心,然后执行150-1000次循环,计算其代价函数,选择其最小的结果。例如
1
2for _ in range(100):
...
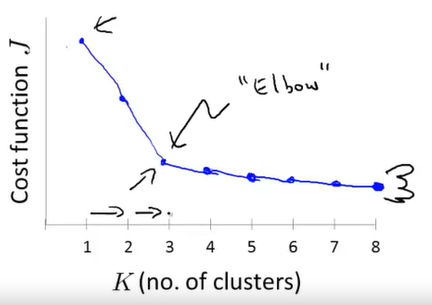
选择K的大小
肘部法则