
函数原型
\[ h_\theta(X)=\frac{1}{1+e^{-\theta^TX}}...称h_\theta(X)为y=1的概率。 \]
决策界限的定义
根据函数表达式可知当\(z>=0\)时\(y>=0.5\)当\(z<0\)时\(y<0.5...z=\theta^TX,y=h_\theta(X)\)
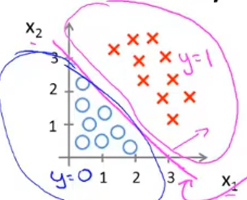
\(故直线z=\theta^TX为决策界限\)
代价函数
线性回归的代价函数为:
\[ J(\theta)=2\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^i)-y(x^i))^2 \]
我们另:
\[ J(\theta)=\frac{1}{m}\sum_{i=1}^{m}Cost(h_\theta(x^i),y(x^i)) \]
\(Cost为:\)
\[ Cost(h_\theta(x^i),y(x^i))=\begin{cases} -log(h_\theta (x))& \text if&y=1\\-log(1-h_\theta (x))& \text if&y=0\end{cases} \]
为什么这样选择?
\(-log(1-h_\theta (x))图像为:\)
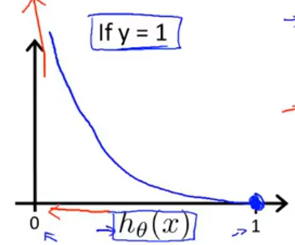
其中
\[ h_\theta(X)=\frac{1}{1+e^{-\theta^TX}}. \]
当\(h_\theta (x)\)无限靠近与0时,代价函数为无穷大。 故\(h_\theta (x)=0\)表示y=1的概率为0,与条件y=1完全矛盾。故给该算法加大惩罚。$
当\(h_\theta (x)\)无限靠近与1时,代价函数为0。 故\(h_\theta (x)=1\)表示y=1的概率为100%,与条件y=1完全符合。
\(-log(1-h_\theta (x))图像为:\)

证明方式与图1类似...
合并代价函数
\[ J(\theta)=\frac{1}{m}\sum_{i=1}^m(-ylog(h_{\theta}(x^i))-(1-y)log(1-h_{\theta}(x^i))) \]
使用梯度下降法迭代
公式与线性回归公式相同。 证明参考:https://blog.csdn.net/qq_29663489/article/details/87276708 ## 多分类问题

思想:二分,归类于y=1概率的的一类。 如图,三个函数同时处理,得到\(h_\theta(X)\),故点归类于\(h_\theta(X)\)大的一类。
d2l 从零实现
读取mnist数据集
1 | import torch |

train
1 | # 前向传播 |
保存参数
1 | torch.save(w, 'w.pt') |
d2l 简洁实现
nn.Flatten与torch.flatten的区别
1 | a = torch.arange(24).reshape((2,3,4)) |
实现
1 | def ac(data_iter, net): |
QA
- net = nn.Sequential(nn.Flatten(), nn.Linear(28*28, 10))为什么没有Softmax层?
- nn.CrossEntropyLoss(reduction='none')?
softmax层在CrossEntropyLoss中:nn.CrossEntropyLoss1
2
3
4
5
6
7loss_func = nn.CrossEntropyLoss()
pre = torch.tensor([[0.8, 0.5, 0.2, 0.5]], dtype=torch.float)
tgt = torch.tensor([[1, 0, 0, 0]], dtype=torch.float)
cross_entropy(0, torch.softmax(pre, dim=1)), loss_func(pre, tgt)
# (tensor([1.1087]), tensor(1.1087))